biblioteca civica di cologno monzese |
VERIFICA SPERIMENTALE
DELL’"EFFETTO D’AUTORE"
Disegno della ricerca ed approfondimento metodologico
A cura di Giuseppe Vergani
La ricerca che abbiamo condotto allo scopo di verificare sperimentalmente quello che definiremo come "effetto d’autore" è motivata dall’obiettivo di comprendere più analiticamente i comportamenti di lettura e le motivazioni ad essi sottostanti. Muovendo dai pochi materiali teorici disponibili su queste tematiche, particolarmente carenti per quel che riguarda il lettore adulto, abbiamo preferito un approccio sperimentale, al fine di testare da subito, all’inizio del nostro percorso conoscitivo, i primi (e semplici) strumenti di cui ci siamo dotati e la pertinenza delle domande che ci siamo posti. Date queste premesse ci sembra opportuno presentare, congiuntamente all’illustrazione del disegno complessivo della ricerca, alcuni approfondimenti relativi ai problemi ed ai risultati metodologici riscontrati, con particolare riferimento alle difficoltà poste dalla misurazione del gradimento del testo.
L’IPOTESI DI RICERCA
L’ipotesi da verificare sperimentalmente è la seguente: a parità di altre condizioni, il giudizio su di un testo dipende dall’informazione sulla notorietà dell’autore.
In altri termini ci poniamo l’obiettivo di misurare come cambia il gradimento di uno stesso testo se siamo o meno informati del grado di notorietà dell’autore.
Definiremo quindi "effetto d’autore" l’incremento relativo di gradimento di un testo introdotto dal sapere che l’autore di quel testo è un autore famoso.
LA POPOLAZIONE DI RIFERIMENTO
La popolazione interessata dall’indagine è l’utenza di sei delle sette biblioteche del Sistema Bibliotecario Nord Est, ed in particolare:
| gli utenti | delle biblioteche di |
| maggiorenni abilitati al prestito per il 1997 residenti nel comune sede di biblioteca |
Brugherio Bussero Carugate Cernusco S/N Cologno Monzese Vimodrone |
I filtri nell’individuazione degli utenti ci permettono di limitare l’indagine ai lettori adulti, di riferirci a utenti "reali", cioè che abbiamo preso in prestito almeno un libro nel corso del 1997 e di contenere la dispersione territoriale dei possibili intervistati. Complessivamente la nostra popolazione di riferimento risulta essere di 7535 lettori, la cui distribuita rispetto alle variabili disponibili nel database delle sei biblioteche è riportata più sotto. Data la numerosità della popolazione ci troviamo di fronte alla necessità di svolgere un’indagine campionaria; le informazioni disponibili ci saranno tuttavia utili per estrarre un campione maggiormente rappresentativo della popolazione.
| GENERE | ||
| donne | 4384 |
58,2 % |
| uomini | 3151 |
41,8 % |
| ETA’ | ||
| 18 - 25 | 3025 |
40,1 % |
| 26 - 35 | 1885 |
25,0 % |
| 36 - 45 | 1367 |
18,1 % |
| 46 - 60 | 919 |
12,2 % |
| oltre 60 | 339 |
4,5 % |
| OCCUPAZIONE LETTORE | ||
| studente superiore | 1332 |
17,7 |
| studente università | 1535 |
20,4 |
| casalinga | 667 |
8,9 |
| pensionato | 409 |
5,4 |
| docente | 494 |
6,6 |
| lav. autonomo | 360 |
4,8 |
| operaio / tecnico | 455 |
6,0 |
| impiegato | 1627 |
21,6 |
| disoccupato | 219 |
2,9 |
| altro | 437 |
5,8 |
DISEGNO DELLA RICERCA
La ricerca si compone di due esperimenti distinti: nel primo, un gruppo di persone leggerà un autore poco noto (che definiremo per comodità "esordiente") credendo invece di leggere un autore molto famoso; un secondo gruppo, quanto più possibile simile al primo almeno relativamente alle caratteristiche che supponiamo influenzino il giudizio su un testo, saprà invece di leggere un esordiente, e costituirà perciò il gruppo di controllo.
Nel secondo esperimento il testo sarà invece di un autore molto noto (I. Calvino): un gruppo sarà indotto a credere di leggere un autore esordiente, mentre il gruppo di controllo saprà la verità. L’identità dell’autore noto non verrà comunque svelata, per limitare l’influenza dei pregiudizi.
La creazione delle condizioni sperimentali presenta due problemi distinti: da una parte si tratta di "ingannare" efficacemente il lettore, dall’altra di costruire quattro gruppi quanto più possibile simili tra di loro (perlomeno simili a due a due) e rappresentativi della popolazione.
L’inganno si realizza allegando al racconto da leggere, privo di qualsiasi possibilità di identificazione, una lettera di presentazione in cui si dichiarerà il vero o il falso rispetto alla notorietà dell’autore del testo; per non influenzare il lettore, non si nomina mai l’esperimento in atto, ma si adducono delle false motivazioni per giustificare la richiesta del suo giudizio sul racconto.
L’esperimento più importante è chiaramente il primo, dove le possibilità di riconoscere l’autore e quindi di "svelare l’inganno" sono remote, e dove quindi non dovrebbero intervenire fattori come il riconoscimento dello stile o della reale identità dell’autore, eventualità ben più probabile nel secondo esperimento.
La costruzione dei gruppi è avvenuta effettuando un’estrazione casuale a strati di quattro campioni di 150 lettori l’uno, stratificati rispetto al genere e all’età; questo significa che la distribuzione dei generi e delle fasce di età all’interno dei quattro campioni sarà (a meno delle inevitabili approssimazioni) identica a quella della popolazione di riferimento. In particolare per ognuno dei quattro gruppi avremo:
| GENERE | gruppi | popolazione | |
| donne | 88 |
58,7 % |
58,2 % |
| uomini | 62 |
41,3 % |
41,8 % |
| Totale | 150 |
100,0 % |
100,0 % |
| ETA’ | gruppi | popolazione | |
| 18 - 25 | 60 |
40,0 % |
40,1 % |
| 26 - 35 | 38 |
25,3 % |
25,0 % |
| 36 - 45 | 27 |
18,0 % |
18,1 % |
| 46 - 60 | 18 |
12,0 % |
12,2 % |
| oltre 60 | 7 |
4,7 % |
4,5 % |
| Totale | 150 |
100,0 % |
100,0 % |
Incorporando nella costruzione dei campioni le informazioni disponibili sulla popolazione e compiendo un’estrazione casuale tra i membri di essa ci garantiamo la rappresentatività con un ristretto margine di errore.
Dato che la realizzazione delle condizioni sperimentali richiede di costruire due coppie di gruppi uguali fra di loro, si sono individuati i due gruppi più simili dal punto di vista della terza variabile disponibile, l’occupazione del lettore (analizzando matematicamente le similarità di questa variabile nei sei accoppiamenti possibili tra i quattro gruppi); la scelta metodologicamente più corretta di stratificare anche per l’occupazione del lettore è risultata impraticabile per la scarsità dei casi appartenenti ad ogni strato.
Individuata la coppia di gruppi che meglio soddisfa le condizioni sperimentali, l’altra coppia (che peraltro presentava un buon coefficiente di similarità) è stata scelta per il secondo esperimento.
Possiamo ora riassumere nello schema seguente il disegno complessivo della verifica sperimentale, che ci mostra la collocazione dei quattro gruppi entro gli assi di notorietà e verità, nonché gli autori scelti per i due esperimenti.
Verità |
|||
Notorietà |
Autore noto Vero Gruppo 2 |
Autore noto Falso Gruppo 4 |
Esperimento 2 (I. Calvino) |
Autore esordiente Vero Gruppo 1 |
Autore esordiente Falso Gruppo 3 |
Esperimento 1 (M. Fortunato) |
|
Gruppi di controllo |
|||
Dato questo disegno sperimentale lo scopo della ricerca sarà quindi, per ognuno dei due esperimenti, quello di misurare la differenza di giudizio tra il gruppo sottoposto alla condizione sperimentale ed il rispettivo gruppo di controllo. L’ipotesi sarà perciò verificata se (riprendendo le definizioni dello schema) il gruppo 3 dichiarerà di apprezzare il racconto più del gruppo 1 e il gruppo 4 manifesterà un apprezzamento minore di quello del gruppo 2.
IL QUESTIONARIO
La raccolta dei dati necessari per l’analisi è avvenuta tramite un questionario allegato al racconto: trattandosi di un questionario autocompilato, dato che ai lettori è stato recapitato a mezzo posta, si è optato per limitare al minimo indispensabile il numero e la complessità delle domande.
Pur con un numero limitato di domande (tredici), il questionario si è rivelato funzionale a diversi obiettivi specifici, quali:
Come si può notare le domande rispondono a due esigenze specifiche. In primo luogo si vogliono ottenere informazioni su quelle che si suppongono essere variabili capaci di influenzare il gradimento di un testo, quali - oltre al sesso, all’età ed all’occupazione del lettore che già abbiamo a disposizione - il livello di istruzione, la quantità e la tipologia delle letture, i consumi culturali, il giudizio sull’autore implicato nel secondo esperimento. Dal punto di vista dell’analisi queste variabili, alle quali si suppone i comportamenti di lettura siano sensibili, sono indispensabili per controllare l’ipotesi sull’"effetto d’autore". Sarà infatti necessario capire se i differenti giudizi sui racconti dipendano dall’informazione sulla notorietà dell’autore o da qualcuna di queste variabili, ed eventualmente (qualora l’ipotesi di ricerca sia verificata) studiare come esse modulino l’esposizione all’"effetto d’autore". Già a questo livello scontiamo il deficit di teoria sui comportamenti di lettura: non è stato infatti possibile verificare se e come queste variabili incidano sull’apprezzamento di un testo, o se siano altre le variabili determinanti.
La seconda (e principale) esigenza - cui corrisponde una seconda classe di domande - è quella di ottenere una quantificazione del gradimento, cioè a dire un indice che esprima su una scala quantitativa la misura in cui il lettore ha apprezzato il racconto che gli è stato proposto. I problemi metodologici di questa operazione sono diversi e piuttosto complessi, e verranno perciò discussi più sotto.
Prima di passare ad analizzare i problemi posti dalla misurazione del gradimento, riassumiamo le classi delle variabili implicate nell’analisi:
Possiamo quindi così riscrivere la nostra ipotesi di ricerca: a parità delle variabili di controllo, l’indicatore di gradimento dipenderà dal gruppo di appartenenza del lettore.
MISURARE IL GRADIMENTO
Quando diciamo "questo libro mi è piaciuto" diamo un’informazione estremamente sintetica, veloce, adatta a sgombrare il terreno comunicativo dalle ambiguità, per poi eventualmente chiarire meglio, modulare le dimensioni del nostro gradimento. Diremo ad esempio che un libro ci è piaciuto perché, pur essendo molto "lento", l’abbiamo trovato ricco di contenuti interessanti; diremo ancora che un secondo libro ci è piaciuto pur motivandone il gradimento con ragioni opposte, cioè giudicandolo un testo assolutamente privo di contenuti, ma molto avvincente.
La semplificazione sopra descritta mostra quali siano i problemi implicati dall’ampiezza del campo semantico del concetto di gradimento. Assumere quindi come indice di gradimento il giudizio complessivo del lettore sul testo può essere particolarmente fuorviante, perlomeno in un duplice senso. Da una parte non sapremmo cosa stiamo misurando: tornando alla precedente esemplificazione, non sapremmo se stiamo misurando l’interesse suscitato nel lettore dai contenuti del testo o il piacere derivante da una narrazione avvincente. In secondo luogo non saremmo in condizioni di conoscere quanto le diverse componenti "pesano" nella formazione del giudizio complessivo, precludendoci una conoscenza più approfondita del fenomeno.
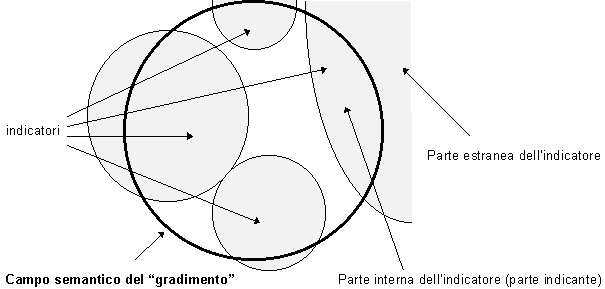
Cerchiamo di chiarire con uno schema quanto detto finora.
Come si diceva più sopra, se il campo semantico di un concetto è troppo esteso, esso è anche molto difficile da misurare. Si tratta allora di scomporre il campo semantico del concetto da misurare nei suoi indicatori, che saranno più facilmente misurabili perché dotati di un campo semantico più ridotto e quindi più agevolmente trasformabili in una variabile. Come si vede nello schema, avremo indicatori più o meno sovrapposti al campo semantico del concetto: l’area in comune tra indicatore e campo semantico del concetto è detta parte indicante, la rimanente area estranea. La parte indicante contribuirà completamente alla misura, mentre l’area estranea riguarderà probabilmente il campo semantico di altri concetti, adiacenti a quello da misurare.
Lo schema ci suggerisce inoltre che non tutti gli indicatori hanno lo stesso peso all’interno del concetto: alcuni coprono un’area semantica più ampia di altri, nella misura in cui la parte indicante degli indicatori è comune all’area del concetto, e quindi contribuiranno con un peso diverso alla misurazione.
La scomposizione del campo semantico, con la conseguente individuazione degli indicatori e la loro trasformazioni in variabili necessita un approfondito lavoro teorico e sperimentale. Innanzitutto, a partire da alcune assunzioni teoriche, verranno individuati degli indicatori che si suppongono un’efficace scomposizione del concetto; in sede di indagine si testa la bontà degli indicatori utilizzati, avvalendosi di strumenti statistici, e l’esito potrà essere di tipo diverso a seconda degli errori della nostra teoria. Potremmo aver individuato indicatori del tutto esterni al campo semantico del concetto, oppure con una piccola componente interna; può darsi che i nostri indicatori siano tutti appartenenti al concetto, ma coprano un’area semantica troppo piccola, e così via. Il nodo cruciale di questa operazione è quindi il lavoro teorico precedente alla ricerca, un lavoro che, per quel che riguarda lo studio del gradimento di un testo da parte del lettore adulto, ci appare largamente insufficiente.
Data la scarsità di conoscenze disponibili abbiamo optato per una doppia semplificazione. Innanzitutto si sono scelti due brevi testi narrativi, due racconti, per rendere ininfluenti altre competenze del lettore che altrimenti avrebbero potuto incidere sul giudizio del testo. In secondo luogo abbiamo scomposto il campo semantico nelle sue componenti più ovvie, quelle per certi versi meno bisognose di ulteriori verifiche sperimentali. In un certo senso abbiamo testato degli indicatori di base, rimandando ad una riflessione successiva (qualora questo primo test dia un esito positivo) ulteriori approfondimenti e verifiche.
Abbiamo chiesto quindi al lettore di esprimere il suo giudizio sul racconto su una scala da 1 (completamente negativo) a 10 (completamente positivo) per i seguenti quattro aspetti:
Abbiamo inoltre chiesto al lettore di esprimere, sulla medesima scala, un giudizio complessivo sul racconto, proprio al fine di studiare l’efficacia della scomposizione attuata.
Il secondo problema metodologico posto dall’operazione di scomposizione del campo semantico è (una volta eseguita la rilevazione dei dati, quando ogni indicatore è rappresentato da una variabile) la ricomposizione degli indicatori in un unico indice sintetico, cioè a dire la costruzione vera e propria della misura del concetto su una scala quantitativa. In buona sostanza il problema è quello di attribuire il giusto peso ad ogni indicatore, dove per peso si intende un fattore di ponderazione che tenga conto della diversa superficie di area semantica del concetto che un indicatore è in grado di ricoprire. Individuato il corretto coefficiente di ponderazione, non ci resta che ricomporre la misura del concetto per via additiva, o meglio per mezzo della media aritmetica ponderata. Va da sé che più gli indicatori rivestono un ruolo simile nella formazione del concetto, minore importanza avrà il calcolo del fattore di ponderazione.
In pratica possiamo operare in due modi, o attraverso la media aritmetica (attribuendo o meno dei pesi derivati dalla teoria o dall’esperienza) o per mezzo dell’analisi fattoriale (factor analisys). Senza addentrarci nei particolari teorici e tecnici della factor analisys, diremo soltanto che questo strumento statistico ci permette di ottenere tre importanti risultati:
Nella verifica sperimentale dell’"effetto d’autore" abbiamo utilizzato entrambi i metodi di ricomposizione, ottenendo buoni risultati in tutte e due i casi. Vediamo ora più nel dettaglio questi risultati, facendo riferimento all’esperimento 1, dove l’effetto d’autore è più evidente.
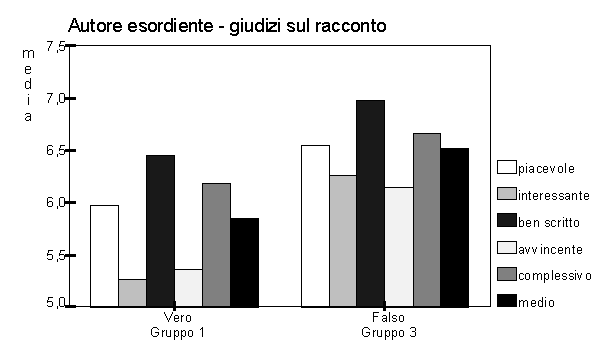
Come si vede l’effetto d’autore è presente per tutti gli indicatori presi singolarmente: questo significa che possiamo affermare che tutti gli indicatori stanno misurando la stessa cosa, e cioè il gradimento del racconto. Anche l’indicatore di controllo, il giudizio complessivo, si comporta secondo l’ipotesi. Questo ci potrebbe far dire che il solo giudizio complessivo era già di per sé una buona misurazione del gradimento. In realtà non abbiamo né a disposizione le necessarie verifiche sperimentali per supportare questa affermazione, né sappiamo se questo possa valere sempre, e non solamente con brevi testi narrativi, dove ad esempio una controcorrelazione tra contenuti e gradimento soggettivo è meno probabile che in altre tipologie di testi.
L’analisi fattoriale dà le medesime indicazioni, confermandole statisticamente: gli indicatori sono molto ben correlati tra i loro e con il gradimento complessivo, quindi decidiamo di inserire anche quest’ultimo tra gli indicatori da assommare nella ricomposizione del gradimento. La factor analisys indica tutti gli indicatori come appartenenti ad un unico fattore, e con pesi vicini all’unità: ne deriviamo che la scomposizione preliminarmente attuata copre con un buon grado di precisione l’area semantica del concetto di gradimento. Possiamo quindi assumere il factor score risultante dall’elaborazione come efficace nel dare una misura quantitativa e sintetica del gradimento di un testo.
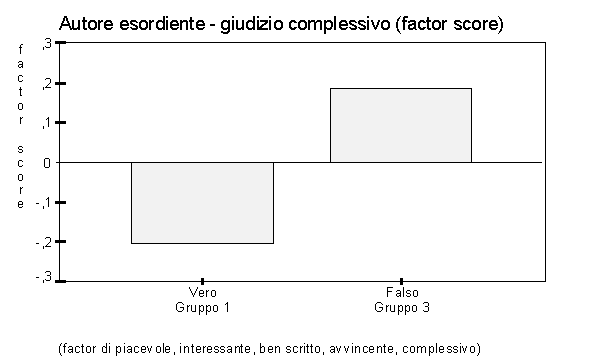
Il factor score esprime la misura in numero puro come scarto dalla media, quindi facilmente interpretabile in termini di differenze relative tra i due gruppi. Vediamo nel grafico sopra riportato come la misura di gradimento complessivo derivata dall’analisi fattoriale renda visibile ed evidente l’"effetto d’autore".
CONCLUSIONI
Come si é cercato di dimostrare con questa ricerca abbiamo ottenuto dei significativi risultati non solo sostanziali, verificando l’ipotesi di ricerca, ma anche metodologici. È importante sottolineare ancora una volta la centralità della questione teorica: il metodo che abbiamo sperimentato e descritto si presenta come un efficace strumento nell’analisi dei comportamenti di lettura, ma non può colmare i vuoti di una riflessione che dev’essere prima teorica, e solo in seguito sperimentale.
| |
pagina a cura di |
ultima revisione |
| URL
di questa pagina: http://www.biblioteca.colognomonzese.mi.it/iniziative/1997/carilettori/Vergani.htm |
||